[data structure] hash(해시)
[data structure] hash(해시)
Hash(해시)
- Hash Or HashTable은 내부적으로 배열을 사용해 데이터를 저장한다.
- 해시 알고리즘을 이용해 고유한 인덱스를 얻는다.
- 인덱스를 이용하여 빠른 검색 속도를 갖는다.
- 해시란 다양한 길이를 가진 데이터를 고정된 길이의 데이터로 매핑한 값을 말한다.
[해시 함수]
- 데이터를 효율적으로 관리하기 위해, 임의의 길이의 데이터를 수학적 연산을 통해 고정된 길이의 데이터로 매핑하는 함수이다. 해시 함수에 의해 얻어지는 값을 해시 코드, 해시라고 한다.
[해시 테이블]
- 키와 값을 매핑해둔 데이터 구조이다. 해시 함수로 얻은 해시를 키로 활용하여 index로 사용하고 해당 index에 데이터를 저장하여 효율적인 검색을 위해 사용된다.
- 동기화를 지원한다.
- key, value에 널 값을 허용하지 않는다.
1
2
3
4
5
6
Lee -> 해시 함수 -> 5
Koo -> 해시 함수 -> 2
Kim -> 해시 함수 -> 1
...
...
Choi -> 해시 함수 -> 5 // Lee와 해싱값 충돌.
결국 데이터가 많아지면, 다른 데이터가 같은 해시 값을 가지게 되어 충돌이 발생하게 된다.
해시 테이블의 근본적인 문제는 결국 index의 충돌이다. 해시는 원래 데이터가 같으면 해시값도 항상 같다. 그러나 서로 다른 데이터 또한 동일한 해시값을 가질 수 있기 때문에 해시 충돌이 발생한다.
-> Collision 현상.
그럼에도 해시 테이블을 쓰는 이유?
적은 자원으로 많은 데이터를 효율적으로 관리하기 위함이다.
하드 디스크나 클라우드에 존재하는 무한한 데이터들을 유한한 개수의 해시값으로 매핑하면 작은 메모리로도 프로세스 관리가 가능해진다.
- 언제나 동일한 해시 값을 리턴, index를 알면 빠른 검색이 가능해진다.
- 해시 테이블의 시간 복잡도 : O(1) [이진 탐색 트리는 O(logN)]
[충돌 해결 방법]
Separate Chaining
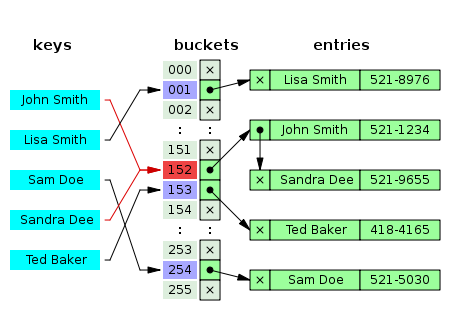
- Key에 대한 index가 가리키는 자료구조를 LinkedList를 이용하는 방식이다.
- index로 인해서 충돌이 발생하면 그 index가 가리키고 있는 LinkedList에 노드를 추가한다.
- 데이터를 검색할 때, 선형 탐색을 하기 때문에 느리다는 단점이 있다.
- 시간 복잡도 : O(N)
- LinkedList 대신 트리를 이용하면 성능을 개선시킬 수 있다.
- JDK 1.8의 경우 index에 노드가 8개 이하인 경우에는 LinkedList를 사용하고 8개를 넘어갈 경우에는 트리 구조로 데이터 저장 구조를 바꾸도록 설계되어 있다.
Open Addressing
- 해시 충돌이 발생하면 해시 함수로 얻은 주소가 아닌 다른 주소 공간에 데이터를 저장하는 방식이다. (해당 키 값에 데이터가 저장되어 있다면 다음 주소에 저장.)
- 선형 탐사(Linear Probing)
- 현재 주소에서 고정 크기(ex.1)만큼 다음 주소로 이동하여 데이터를 저장한다.
- 제곱 탐사(Quadratic Probing)
- 고정 크기만큼 이동하는 것이 아닌 이동 크기가 제곱수로 늘어나는 방식이다. (1,4,9,16…)
- 이중 해싱(Double Hashing)
- 해시 충돌 시 다른 해시 함수를 한번 더 적용하는 방식이다.
- 재해싱(Rehashing)
- 해시 테이블의 크기를 늘리고, 늘어난 해시 테이블의 크기에 맞추어 모든 데이터를 다시 해싱하는 방식이다.
Open Addressing 방식은 삭제 처리시에 문제가 발생할 수 있다.
데이터 A를 저장하고 데이터 B를 저장할 때 충돌(A와 같은 값)이 발생한다고 가정하자.
이때, 데이터 A가 삭제될 경우 찾으려고 하는 index를 찾기 전에 데이터가 삭제되어서 검색을 멈추기 때문에 데이터 B를 조회할 수 없게 된다.
이러한 문제점을 해결하기 위해 데이터를 삭제한 후에 더미 노드를 삽입한다. 실제로 값을 가지진 않지만 검색 시 다음 index까지 연결하는 역할을 한다. 데이터 삭제가 빈번하여 더미 노드가 증가한 경우, 조회할 데이터가 존재하지 않음에도 불구하고 더미 노드 때문에 검색을 수행하므로 더미 노드가 일정 갯수가 넘어가면 해시 테이블을 리빌딩해야 한다.
HashTable ve HashMap
- HashMap : Map 인터페이스를 구현하기 위해 HashTable을 사용한 클래스로 key와 value에 Null이 허용된다. 동기화를 지원하지 않는다.
- HashTable : HashMap보다 속도는 느리지만, 동기화를 지원하며 key와 value에 null이 허용되지 않는다.
읽어보면 좋은 글
This post is licensed under
CC BY 4.0
by the author.